
 Does a PhD Pay Off?Every week, I discuss with people who want to get a PhD. For years, I have been advising people not to pursue a PhD. It may come as a surprise to some. You would expect people with a PhD to earn more money. Individuals who complete doctorates tend to have higher cognitive abilities and greater … Continue reading Does a PhD Pay Off?Daniel Lemire's blog
Does a PhD Pay Off?Every week, I discuss with people who want to get a PhD. For years, I have been advising people not to pursue a PhD. It may come as a surprise to some. You would expect people with a PhD to earn more money. Individuals who complete doctorates tend to have higher cognitive abilities and greater … Continue reading Does a PhD Pay Off?Daniel Lemire's blogC++ Blogs, the last 7 days
Friday, July 24, 2026
Does a PhD Pay Off?Every week, I discuss with people who want to get a PhD. For years, I have been advising people not to pursue a PhD. It may come as a surprise to some. You would expect people with a PhD to earn more money. Individuals who complete doctorates tend to have higher cognitive abilities and greater … Continue reading Does a PhD Pay Off?Daniel Lemire's blog Making an agile version of a Windows Runtime delegate in C++/WinRT, part 5Making sure to use the non-agile delegate non-agile-ly. The post Making an agile version of a Windows Runtime delegate in C++/WinRT, part 5 appeared first on The Old New Thing .The Old New Thing
Making an agile version of a Windows Runtime delegate in C++/WinRT, part 5Making sure to use the non-agile delegate non-agile-ly. The post Making an agile version of a Windows Runtime delegate in C++/WinRT, part 5 appeared first on The Old New Thing .The Old New Thing Introducing Logarithmic Quantities and UnitsIntroducing Logarithmic Quantities and Units Decibels are everywhere in engineering. Signal levels in dBm , sound pressure in dB SPL , voltage gain in dB , filter slopes in dB/octave . The neper, pH, and stellar magnitude share the same structure. Yet, to the best of our knowledge, no general-purpose units library models logarithmic quantities correctly. Most do not model them at all. The few that do treat a decibel as a non-linear scale or an offset unit, and that choice gets the arithmetic wrong in ways that compile silently. This article is a request for feedback . We believe we have a correct design, derived from the same affine-space model we introduced for absolute quantities . It also aims to stay consistent with the ISO/IEC 80000 standards: especially IEC 80000-15:2026, Logarithmic quantities and their units , which consolidates the logarithmic-quantity rules once held in ISO 80000-1:2009 (Annex C); together with ISO 80000-2 (the logarithm functions lb , ln , lg ), ISO 80000-8 (acoustics), and IEC 80000-13 (information theory). We have read those against this design, cite them throughout, and call out the one place we knowingly diverge from them ( Open Question 5 ). This post describes the design in full, from the quantity spec to the named units, the arithmetic, the conversions, and every domain we surveyed (audio, RF, acoustics, chemistry, astronomy, music, information theory). Then it lays out the open questions , each with every alternative we considered and our current preference. Before we implement any of this in mp-units , we want the people who use these quantities daily to tell us where we are wrong.mp-units
Introducing Logarithmic Quantities and UnitsIntroducing Logarithmic Quantities and Units Decibels are everywhere in engineering. Signal levels in dBm , sound pressure in dB SPL , voltage gain in dB , filter slopes in dB/octave . The neper, pH, and stellar magnitude share the same structure. Yet, to the best of our knowledge, no general-purpose units library models logarithmic quantities correctly. Most do not model them at all. The few that do treat a decibel as a non-linear scale or an offset unit, and that choice gets the arithmetic wrong in ways that compile silently. This article is a request for feedback . We believe we have a correct design, derived from the same affine-space model we introduced for absolute quantities . It also aims to stay consistent with the ISO/IEC 80000 standards: especially IEC 80000-15:2026, Logarithmic quantities and their units , which consolidates the logarithmic-quantity rules once held in ISO 80000-1:2009 (Annex C); together with ISO 80000-2 (the logarithm functions lb , ln , lg ), ISO 80000-8 (acoustics), and IEC 80000-13 (information theory). We have read those against this design, cite them throughout, and call out the one place we knowingly diverge from them ( Open Question 5 ). This post describes the design in full, from the quantity spec to the named units, the arithmetic, the conversions, and every domain we surveyed (audio, RF, acoustics, chemistry, astronomy, music, information theory). Then it lays out the open questions , each with every alternative we considered and our current preference. Before we implement any of this in mp-units , we want the people who use these quantities daily to tell us where we are wrong.mp-unitsIf this page is useful, please consider donating a coffee
Thursday, July 23, 2026
 The PImpl idiom and the C++26 std::indirect typePImpl (which stands for Pointer to implementation) is a programming tehnicque to remove implementation details from a class by placing them in a separate class that is accessed through an opaque pointer. Its purpose is to separate interfaces and implementations and minimize compile-time dependencies. In this article, we’ll at how the PImpl idiom is typically ... Read more The post The PImpl idiom and the C++26 std::indirect type first appeared on Marius Bancila's Blog .Marius Bancila's Blog
The PImpl idiom and the C++26 std::indirect typePImpl (which stands for Pointer to implementation) is a programming tehnicque to remove implementation details from a class by placing them in a separate class that is accessed through an opaque pointer. Its purpose is to separate interfaces and implementations and minimize compile-time dependencies. In this article, we’ll at how the PImpl idiom is typically ... Read more The post The PImpl idiom and the C++26 std::indirect type first appeared on Marius Bancila's Blog .Marius Bancila's Blog Making an agile version of a Windows Runtime delegate in C++/WinRT, part 4Optimizing the context check. The post Making an agile version of a Windows Runtime delegate in C++/WinRT, part 4 appeared first on The Old New Thing .The Old New Thing
Making an agile version of a Windows Runtime delegate in C++/WinRT, part 4Optimizing the context check. The post Making an agile version of a Windows Runtime delegate in C++/WinRT, part 4 appeared first on The Old New Thing .The Old New Thing Security advisory: CVE-2026-15037 - XML injection vulnerability in QDom comment, CDATA and processing-instruction serializationAn XML injection (improper output neutralization) vulnerability in the Qt XMLQDom comment, CDATA section, and processing-instruction serialization of the Qt Framework (QtXml module) has been discovered and has been assigned the CVE id CVE-2026-15037.Qt Blog
Security advisory: CVE-2026-15037 - XML injection vulnerability in QDom comment, CDATA and processing-instruction serializationAn XML injection (improper output neutralization) vulnerability in the Qt XMLQDom comment, CDATA section, and processing-instruction serialization of the Qt Framework (QtXml module) has been discovered and has been assigned the CVE id CVE-2026-15037.Qt BlogWednesday, July 22, 2026
 Pure Virtual C++ 2026 Is a WrapPure Virtual C++ 2026 is a wrap. Every featured and on-demand session is now available on YouTube — catch up on C++/Rust interop, AI-driven tooling, build performance, and more. The post Pure Virtual C++ 2026 Is a Wrap appeared first on C++ Team Blog .C++ Team Blog
Pure Virtual C++ 2026 Is a WrapPure Virtual C++ 2026 is a wrap. Every featured and on-demand session is now available on YouTube — catch up on C++/Rust interop, AI-driven tooling, build performance, and more. The post Pure Virtual C++ 2026 Is a Wrap appeared first on C++ Team Blog .C++ Team Blog From Institutions to Individuals: the White House Report on Revitalizing U.S. Scientific LeadershipIn 1945, Vannevar Bush published a report entitled Science: The Endless Frontier. His thesis was that prosperity follows from basic research. The report was highly influential in the United States and elsewhere. It led to the creation of an entirely new government bureaucracy. With this report, Bush popularized the linear model of innovation: innovation (such … Continue reading From Institutions to Individuals: the White House Report on Revitalizing U.S. Scientific LeadershipDaniel Lemire's blogMaking an agile version of a Windows Runtime delegate in C++/WinRT, part 3The object that actively refuses to be marshaled. The post Making an agile version of a Windows Runtime delegate in C++/WinRT, part 3 appeared first on The Old New Thing .The Old New Thing
From Institutions to Individuals: the White House Report on Revitalizing U.S. Scientific LeadershipIn 1945, Vannevar Bush published a report entitled Science: The Endless Frontier. His thesis was that prosperity follows from basic research. The report was highly influential in the United States and elsewhere. It led to the creation of an entirely new government bureaucracy. With this report, Bush popularized the linear model of innovation: innovation (such … Continue reading From Institutions to Individuals: the White House Report on Revitalizing U.S. Scientific LeadershipDaniel Lemire's blogMaking an agile version of a Windows Runtime delegate in C++/WinRT, part 3The object that actively refuses to be marshaled. The post Making an agile version of a Windows Runtime delegate in C++/WinRT, part 3 appeared first on The Old New Thing .The Old New Thing CLion’s Classic Engine Unbundled: What’s NextLast year, we announced that CLion Nova would become the default C and C++ engine for all users and that all new language improvements would be developed for Nova. With CLion 2026.2, we’re taking the next step in that transition – the legacy Classic engine is moving from the CLion bundle to an optional plugin. […]CLion : A Cross-Platform IDE for C and C++ | The JetBrains Blog
CLion’s Classic Engine Unbundled: What’s NextLast year, we announced that CLion Nova would become the default C and C++ engine for all users and that all new language improvements would be developed for Nova. With CLion 2026.2, we’re taking the next step in that transition – the legacy Classic engine is moving from the CLion bundle to an optional plugin. […]CLion : A Cross-Platform IDE for C and C++ | The JetBrains BlogTuesday, July 21, 2026
 The Portable Way to Extract Date and Time from a File's mtime in C++After I finished my Time in C++ series, a reader asked a seemingly simple question: “What is the portable way to extract the year, month, day, hour, minute, and second from a file’s modification time? I tried, and I couldn’t get it to work reliably on macOS and Windows.” Fair question. You call std::filesystem::last_write_time(), you get back a time point, and you want the calendar compon...Sandor Dargo's Blog
The Portable Way to Extract Date and Time from a File's mtime in C++After I finished my Time in C++ series, a reader asked a seemingly simple question: “What is the portable way to extract the year, month, day, hour, minute, and second from a file’s modification time? I tried, and I couldn’t get it to work reliably on macOS and Windows.” Fair question. You call std::filesystem::last_write_time(), you get back a time point, and you want the calendar compon...Sandor Dargo's Blog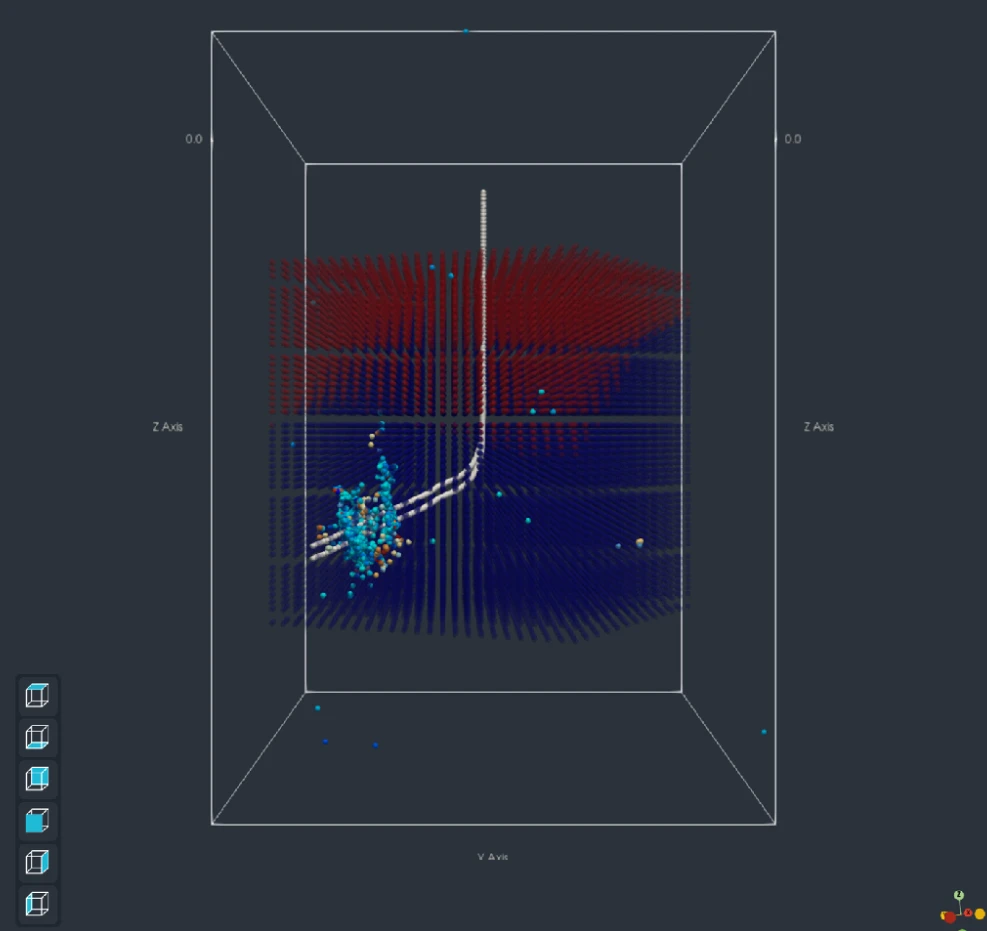 Look Up Geoscience uses ParaView to improve subsurface visualizationThis is a guest blog post from Nicolas Cami and Florian Carnac from Look up Geoscience. They share their recent work using ParaView as a framework for EarthSight™ software. Thanks to their innovative approach using QML in ParaView, they created a nice-looking application to help with subsurface modeling, simulation, and visualization. Subsurface modeling software has […]Kitware Inc
Look Up Geoscience uses ParaView to improve subsurface visualizationThis is a guest blog post from Nicolas Cami and Florian Carnac from Look up Geoscience. They share their recent work using ParaView as a framework for EarthSight™ software. Thanks to their innovative approach using QML in ParaView, they created a nice-looking application to help with subsurface modeling, simulation, and visualization. Subsurface modeling software has […]Kitware Inc Prefactoring: Clear the Way for Your New Feature@media only screen and (max-width: 600px) { .body { overflow-x: auto; } .post-content table, .post-content td { width: auto !important; white-space: nowrap; } } This article was adapted from a Google Tech on the Toilet (TotT) episode. You can download a printer-friendly version of this TotT episode and post it in your office. By Rahul Singal “First make the change easy, then make the easy change.” - paraphrased from Kent Beck You're working on a new feature, but the existing code wasn't written with future changes in mind. Trying to force the feature in directly gets complicated fast. One change leads to another, and before you know it you're already a few files deep fixing things you never planned to touch. Prefactoring (short for "preparatory refactoring") is the practice of reworking existing code to make it more suitable for an upcoming change before you actually implement the new functionality. Instead of cleaning up code as an afterthought or trying to force a new feature into an incompatible structure, you restructure the codebase first. Prefactoring helps you: Easily implement new features: Restructuring the codebase first ensures your new feature fits naturally into the code. Speed up reviews: It's easier to review the refactoring and the feature in separate changes. Avoid bugs: Isolating cleanups from functional logic can help prevent bugs . Roll back safely: If you need to roll back, it is much easier to revert small, focused changes. Here is a simplified example of a prefactoring change: Change 1 (Prefactoring) Extract display name helper to remove duplication. Change 2 (Feature) Add middle name support. + def get_display_name(user): + return f"{user.first_name}” {user.last_name} # Profile page - display_name = f"{user.first_name} {user.last_name}" + display_name = get_display_name(user) # Email template - greeting = f"Hi {user.first_name} {user.last_name}, " + greeting = f"Hi {get_display_name(user)}," def get_display_name(user): - return f"{user.first_name} {user.last_name}” + return f"{user.first_name} {user.middle_name} {user.last_name}" You can prefactor a change that is already in review too! If your reviewer suggests a related cleanup during review, you can also extract it into a new base change to keep your current change focused on the feature. Note that not every cleanup needs to be prefactoring: you can do the cleanup in a follow up change if the cleanup doesn’t block your feature, or even in the same change if the cleanup is small enough.Google Testing BlogPure Virtual C++ 2026 Is Now Live!Pure Virtual C++ 2026 is streaming now — watch five featured sessions live with Q&A, plus a full on-demand playlist, all free. The post Pure Virtual C++ 2026 Is Now Live! appeared first on C++ Team Blog .C++ Team BlogMaking an agile version of a Windows Runtime delegate in C++/WinRT, part 2Short-circuiting the easiest case. The post Making an agile version of a Windows Runtime delegate in C++/WinRT, part 2 appeared first on The Old New Thing .The Old New ThingSecurity advisory: Out-of-bounds read vulnerability in QTextCodec::codecForName() in QtAn out-of-bounds read (buffer over-read) vulnerability in the QTextCodec::codecForName() function of the Qt 5 Core Compatibility APIs (the Qt5Compat module) has been discovered and has been assigned the CVE id CVE-2026-9499Qt Blog
Prefactoring: Clear the Way for Your New Feature@media only screen and (max-width: 600px) { .body { overflow-x: auto; } .post-content table, .post-content td { width: auto !important; white-space: nowrap; } } This article was adapted from a Google Tech on the Toilet (TotT) episode. You can download a printer-friendly version of this TotT episode and post it in your office. By Rahul Singal “First make the change easy, then make the easy change.” - paraphrased from Kent Beck You're working on a new feature, but the existing code wasn't written with future changes in mind. Trying to force the feature in directly gets complicated fast. One change leads to another, and before you know it you're already a few files deep fixing things you never planned to touch. Prefactoring (short for "preparatory refactoring") is the practice of reworking existing code to make it more suitable for an upcoming change before you actually implement the new functionality. Instead of cleaning up code as an afterthought or trying to force a new feature into an incompatible structure, you restructure the codebase first. Prefactoring helps you: Easily implement new features: Restructuring the codebase first ensures your new feature fits naturally into the code. Speed up reviews: It's easier to review the refactoring and the feature in separate changes. Avoid bugs: Isolating cleanups from functional logic can help prevent bugs . Roll back safely: If you need to roll back, it is much easier to revert small, focused changes. Here is a simplified example of a prefactoring change: Change 1 (Prefactoring) Extract display name helper to remove duplication. Change 2 (Feature) Add middle name support. + def get_display_name(user): + return f"{user.first_name}” {user.last_name} # Profile page - display_name = f"{user.first_name} {user.last_name}" + display_name = get_display_name(user) # Email template - greeting = f"Hi {user.first_name} {user.last_name}, " + greeting = f"Hi {get_display_name(user)}," def get_display_name(user): - return f"{user.first_name} {user.last_name}” + return f"{user.first_name} {user.middle_name} {user.last_name}" You can prefactor a change that is already in review too! If your reviewer suggests a related cleanup during review, you can also extract it into a new base change to keep your current change focused on the feature. Note that not every cleanup needs to be prefactoring: you can do the cleanup in a follow up change if the cleanup doesn’t block your feature, or even in the same change if the cleanup is small enough.Google Testing BlogPure Virtual C++ 2026 Is Now Live!Pure Virtual C++ 2026 is streaming now — watch five featured sessions live with Q&A, plus a full on-demand playlist, all free. The post Pure Virtual C++ 2026 Is Now Live! appeared first on C++ Team Blog .C++ Team BlogMaking an agile version of a Windows Runtime delegate in C++/WinRT, part 2Short-circuiting the easiest case. The post Making an agile version of a Windows Runtime delegate in C++/WinRT, part 2 appeared first on The Old New Thing .The Old New ThingSecurity advisory: Out-of-bounds read vulnerability in QTextCodec::codecForName() in QtAn out-of-bounds read (buffer over-read) vulnerability in the QTextCodec::codecForName() function of the Qt 5 Core Compatibility APIs (the Qt5Compat module) has been discovered and has been assigned the CVE id CVE-2026-9499Qt BlogMonday, July 20, 2026
 C++ Dependencies Without the Headache: vcpkg + Copilot CLIAt Pure Virtual C++ 2026, we build a C++ console app from an empty folder using CMake, MSVC, and GitHub Copilot CLI. This walkthrough shows a practical prompt sequence for dependency selection, reproducible builds, and controlled updates. The post C++ Dependencies Without the Headache: vcpkg + Copilot CLI appeared first on C++ Team Blog .C++ Team BlogPure Virtual C++ 2026 Is Tomorrow and On-Demand Sessions Are Now AvailableThe on-demand sessions for Pure Virtual C++ 2026 are available now on YouTube. Watch seven talks on SPGO, vcpkg + Copilot CLI, CMake Tools, PackageReference, MSVC upgrades, and C++23/26 status — then join us live tomorrow. The post Pure Virtual C++ 2026 Is Tomorrow and On-Demand Sessions Are Now Available appeared first on C++ Team Blog .C++ Team BlogMaking an agile version of a Windows Runtime delegate in C++/WinRT, part 1The easy case is easy. The post Making an agile version of a Windows Runtime delegate in C++/WinRT, part 1 appeared first on The Old New Thing .The Old New Thing
C++ Dependencies Without the Headache: vcpkg + Copilot CLIAt Pure Virtual C++ 2026, we build a C++ console app from an empty folder using CMake, MSVC, and GitHub Copilot CLI. This walkthrough shows a practical prompt sequence for dependency selection, reproducible builds, and controlled updates. The post C++ Dependencies Without the Headache: vcpkg + Copilot CLI appeared first on C++ Team Blog .C++ Team BlogPure Virtual C++ 2026 Is Tomorrow and On-Demand Sessions Are Now AvailableThe on-demand sessions for Pure Virtual C++ 2026 are available now on YouTube. Watch seven talks on SPGO, vcpkg + Copilot CLI, CMake Tools, PackageReference, MSVC upgrades, and C++23/26 status — then join us live tomorrow. The post Pure Virtual C++ 2026 Is Tomorrow and On-Demand Sessions Are Now Available appeared first on C++ Team Blog .C++ Team BlogMaking an agile version of a Windows Runtime delegate in C++/WinRT, part 1The easy case is easy. The post Making an agile version of a Windows Runtime delegate in C++/WinRT, part 1 appeared first on The Old New Thing .The Old New Thing A Special General Meeting has been scheduledThe ACCU Committee has scheduled an online Special General Meeting for 19th September, 2026 at 19:00 BST. More information can be found on the AGM page (members only - must be logged in).ACCU
A Special General Meeting has been scheduledThe ACCU Committee has scheduled an online Special General Meeting for 19th September, 2026 at 19:00 BST. More information can be found on the AGM page (members only - must be logged in).ACCU